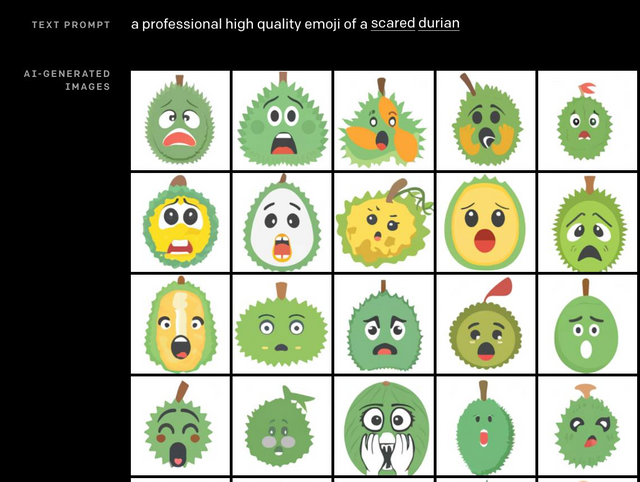
I finally got some time to play with the example results from DALL-E, the new generative network from OpenAI, and it’s amazing. I’ve been watching the space of image-generative networks for a few years, wondering when we’d get past the uncanny valley. We got there for faces with StyleGAN at the beginning of 2019, but it appears we might be past the uncanny valley now for a whole class of clip art and creative stock imagery. This is exciting, as we may not be too far from an infinite stock photography library, where you could ask the system for “a tall man with light brown skin and black hair drinking tea while sitting in a café in the English countryside” and get a range of computer-generated examples to pick from.
DALL-E takes a text input (eg “An illustration of a baby penguin with headphones skating on ice”), encodes it using a GPT3-style transformer network, and then uses an autoregressive image decoder to produce a series of image instances of that input. Depending on the task challenge, it can produce realistic output that matches the input text string in a variety of styles. While OpenAI is not freely letting people run the network, they provide a combinatorially large number of examples to play with.
The paper still isn’t out, so a lot of the pieces of the architecture are not clear. For now, there’s a blog post:https://openai.com/blog/dall-e/
I’m way less well versed in transformer networks than I am in convolutional image networks, so some of these conclusions may be off-base. With that caveat, here are some things I’ve noticed:

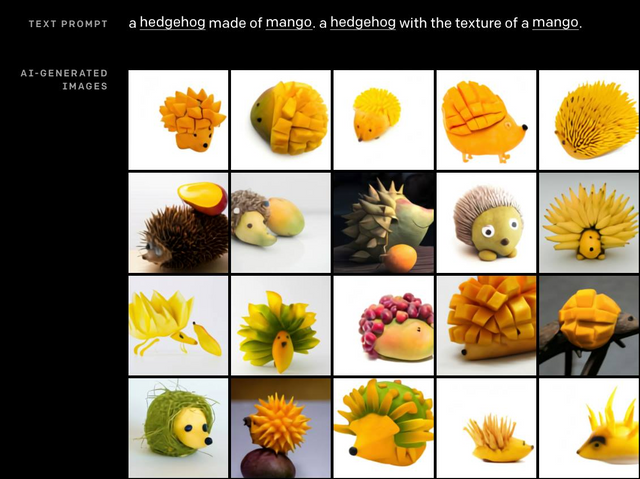
- As long as the concept isn’t too weird, the network tends to do really well, at least as well as you’d get by farming the task out to a low-commitment artist contest on a 99designs type site. Given that, it could work well as design inspiration for artists, and in some cases, actual designs that are ready for use. It won’t replace good art, but it can replace mediocre art. Check out the “An illustration of a baby penguin with headphones skating on ice” example for an illustration, and “A hedgehog with the texture of a mango” for an example of an attempt at photorealism.

- If you give it something really weird, it tends to struggle. “An illustration of a baby bok choy in a cape writing a letter” creates some poor results. Would a bok choy wear a cape like this? Or like this? Is the leafy part already a cape? Do bok choys have arms or do they write letters telekinetically?

- Unusual words are hard for the system. There probably aren’t a lot of training examples of heptagons, so the system struggles when asked to draw a heptagonal stop sign.
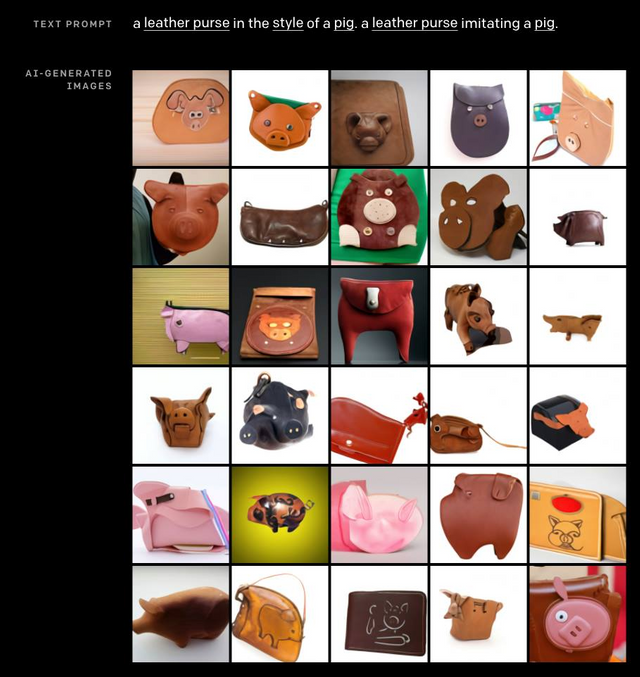
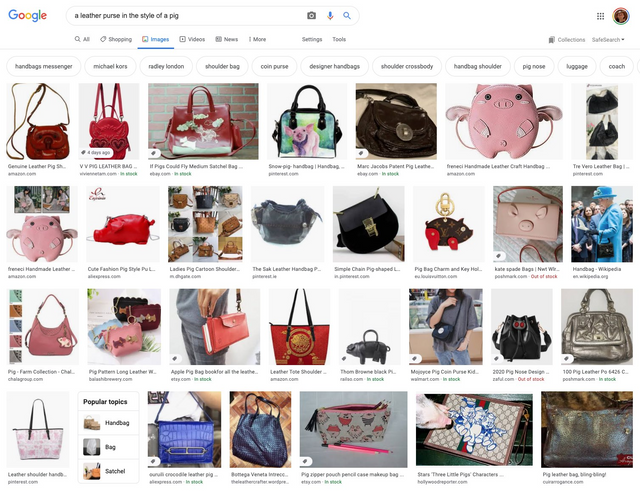
- It doesn’t appear to be directly storing or building off of real world examples. Check out generated examples for “a leather purse in the style of a pig” vs actual purses in this style I found with google image search.

- Direct translations of text into the image (eg “a t-shirt that has the word “hogwash” written on it”) are not past the uncanny valley yet, but it’s amazing that this technique works at all.
- DALL-E uses a completely separate image-classification network (CLIP) with a different architecture to check its work, and this improves its performance dramatically.
More generally:
- Really big (multi-billion-parameter) transformer networks are doing an impressive job of generalizing across a range of tasks and performing second-order reasoning about concepts it’s given. People managed to get amazing zero-shot learning behavior out of GPT3 by priming it with text like “Please unscramble the letters into a word, and write that word: asnico” to get GPT3 to solve anagrams. DALL-E does a similarly good job with a wide range of text prompts for images.
- Transformer networks for generating images appear to be outperforming pure convolutional approaches in a lot of cases. Given the impressive performance of GPT3 on a range of reasoning tasks, it’s likely that the language network may be doing a lot of the heavy lifting of mapping visual concepts in the image into a useful form. For example, the spatial relations in “A blue sphere is sitting on top of a red cube, and they’re both inside a fishbowl” are almost certainly being encoded on the language side as opposed to being abstract concepts that are understood by the image decoder.
- Autoregressive generative image models like DALL-E and VQ-VAE-2, where the image is created a pixel at a time in scanlines from the top left to the bottom right, make me a bit uncomfortable, intellectually speaking. They don’t match my intuition about how humans conceive of and draw illustrations, whereas convolutional networks do. However, it may be that the powerful element of autoregressive image models is the attention mechanism, not the sequential production of an image via scanlines. In any case, I can’t argue with the output. The results are really good.
- A lot of getting DALL-E to perform (as well as GPT3) is about unlocking the right phrasing when explaining the task to the language model. In the examples, the authors often pass the same task description phrased two or three different ways to get it to work. This seems less than ideal, but given the high cost of training a network like GPT3, we’ll probably see a lot of this. Figuring out the right phrasing by generating a range of examples and checking out the results is a lot less work than retraining GPT3 to make it better.
- The use of CLIP to filter DALL-E’s results speaks to a new style of network engineering. Going forward, I’m guessing that a lot of complex tasks will be accomplished by “gluing” a set of large pretrained neural networks together (possibly with the addition of a handful of smaller custom-trained networks) such that the deficiencies of any one of the networks are moderated by other networks.
While DALL-E is not available for general use, there is a free site called www.artbreeder.com that allows you to combine visual concepts of different categories of objects. It tends to be best as visual inspiration for artists, though in some specific categories (eg anime characters) it does very well at producing something usable on its own.