Not easy but real cool
I am quite busy coding and trying new things in order to get cool subtitles and transcripts. Listening to a long podcast you might want to skip to more interesting parts or quote people, click on links. Having interactive transcripts on Steem(it) is the ultimate goal. If you have every been on Coursera you know how cool they are!
But we are not there yet!
It's editing who said what on YouTube (for now) but this takes a lot of time for me alone. And I am much better at figuring out how to make cool stuff and improve the Steem experience.
How you can help
Upload your (Whaletank) talks or any of podcast and interviews to YouTube or use Google Cloud to get quality transcripts. On YouTube they are free but it might take a couple of hours. However on YouTube you can edit them really nicely and make your interviews, talks and podcast much more engaging.
Automate as much as you can
Now we use Mumble to record mutlichannel so that each speaker can easily be identified. You get a file for each speaker like this:
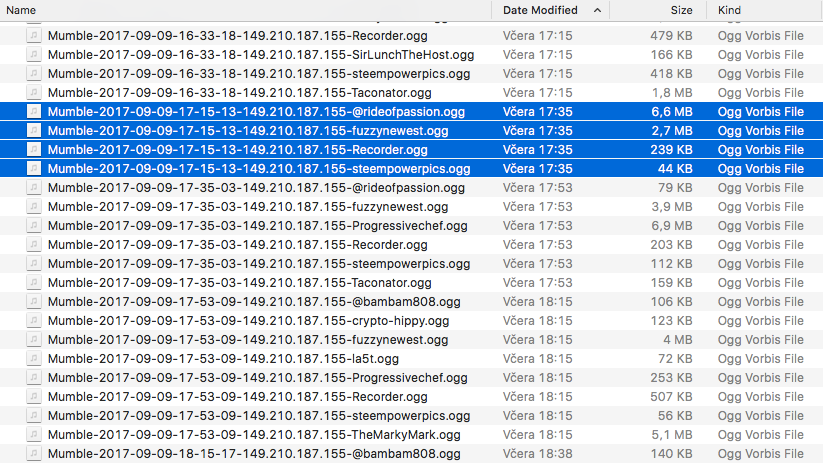
Then you can batch convert them to movies
for file in *; do ffmpeg -loop 1 -r 2 -i "$img" -i "$file" -vf scale=-1:380 -c:v libx264 -preset slow -tune stillimage -crf 18 -c:a copy -shortest -pix_fmt yuv420p -threads 0 "$file".mkv; done
and upload them to YouTube
Stack Overflow
Solving technical issues
I'm trying to solve some technical issues right now like for example why ffmpeg shortens the talks when I mix all the track from the speakers down to stereo. Also merging subtitles gives unexpected results since sometimes people talk over each other.
So would you like to join me in making experience on Steem(it) better, cooler and more fun? And learn some cool tricks along the way? Let me know in the comments how you like the idea and we can discuss how you can help or promote this project or you can upvote & resteem. Questions are welcome too of course!
StackOverflow
We record talks through Mumble and because Mumble has a nitfy multichannel feature I'd figured we could get subtitles from YouTube by uploading each track to YouTube separately with for file in *; do ffmpeg -loop 1 -r 2 -i "$img" -i "$file" -vf scale=-1:380 -c:v libx264 -preset slow -tune stillimage -crf 18 -c:a copy -shortest -pix_fmt yuv420p -threads 0 "$file".mkv; done I then can prepend with a eg. a sed shell script a nickname for each speaker in the automatic captions i.e. subtitles from YouTube. Works like a charm.
But merging those tracks with ffmpeg gets tricky. I use ffmpeg -i input1.ogg -input2.ogg -i input3.ogg -i input4.ogg -input5.ogg -filter_complex "[0:a][1:a][2:a][3:a][4:a] amerge=inputs=5[aout]" -map "[aout]" -ac 2 output.ogg
Somehow ffmpeg shortens the resulting audio track and I don't yet have an idea why. I tried using the longest first and last since including silent tracks made even a shorter mixdown. Here are the warnings:
[Parsed_amerge_0 @ 0x7f8b29f02d20] No channel layout for input 1
[Parsed_amerge_0 @ 0x7f8b29f02d20] Input channel layouts overlap: output layout will be determined by the number of distinct input channels
But it says
[Parsed_amerge_0 @ 0x7f8b29f02d20] No channel layout for input 1
even when I change the order of inputs.
Allthough according to Mumble's documentation the tracks should be equal length VLC media info shows different track times. However the tracks are not out of sync just cut off at the end.
I also have no idea why ffmpeg mentions FLAC, all the files are vorbis.
ffmpeg -i Mumble-2017-09-09-16-33-18-149.210.187.155-chrisaiki2.ogg -i Mumble-2017-09-09-16-33-18-149.210.187.155-Recorder.ogg -i Mumble-2017-09-09-16-33-18-149.210.187.155-steempowerpics.ogg -i Mumble-2017-09-09-16-33-18-149.210.187.155-Taconator.ogg -i Mumble-2017-09-09-16-33-18-149.210.187.155-fuzzynewest.ogg -filter_complex "[0:a][1:a][2:a][3:a][4:a] amerge=inputs=5[aout]" -map "[aout]" -ac 2 output5.ogg
ffmpeg version 2.8.4 Copyright (c) 2000-2015 the FFmpeg developers
built with Apple LLVM version 7.0.2 (clang-700.1.81)
configuration: --prefix=/usr/local/Cellar/ffmpeg/2.8.4 --enable-shared -- enable-pthreads --enable-gpl --enable-version3 --enable-hardcoded-tables --enable- avresample --cc=clang --host-cflags= --host-ldflags= --enable-opencl --enable- libx264 --enable-libmp3lame --enable-libvo-aacenc --enable-libxvid --enable-vda
libavutil 54. 31.100 / 54. 31.100
libavcodec 56. 60.100 / 56. 60.100
libavformat 56. 40.101 / 56. 40.101
libavdevice 56. 4.100 / 56. 4.100
libavfilter 5. 40.101 / 5. 40.101
libavresample 2. 1. 0 / 2. 1. 0
libswscale 3. 1.101 / 3. 1.101
libswresample 1. 2.101 / 1. 2.101
libpostproc 53. 3.100 / 53. 3.100
Input #0, ogg, from 'Mumble-2017-09-09-16-33-18-149.210.187.155- chrisaiki2.ogg':
Duration: 00:40:01.19, start: 0.000000, bitrate: 17 kb/s
Stream #0:0: Audio: vorbis, 48000 Hz, mono, fltp, 86 kb/s
Metadata:
ENCODER : libsndfile
TITLE : chrisaiki2
Input #1, ogg, from 'Mumble-2017-09-09-16-33-18-149.210.187.155-Recorder.ogg':
Duration: 00:33:57.88, start: 0.000000, bitrate: 1 kb/s
Stream #1:0: Audio: vorbis, 48000 Hz, mono, fltp, 86 kb/s
Metadata:
ENCODER : libsndfile
TITLE : Recorder
Input #2, ogg, from 'Mumble-2017-09-09-16-33-18-149.210.187.155-steempowerpics.ogg':
Duration: 00:33:53.93, start: 0.000000, bitrate: 1 kb/s
Stream #2:0: Audio: vorbis, 48000 Hz, mono, fltp, 86 kb/s
Metadata:
ENCODER : libsndfile
TITLE : steempowerpics
Input #3, ogg, from 'Mumble-2017-09-09-16-33-18-149.210.187.155-Taconator.ogg':
Duration: 00:35:36.37, start: 0.000000, bitrate: 6 kb/s
Stream #3:0: Audio: vorbis, 48000 Hz, mono, fltp, 86 kb/s
Metadata:
ENCODER : libsndfile
TITLE : Taconator
Input #4, ogg, from 'Mumble-2017-09-09-16-33-18-149.210.187.155-fuzzynewest.ogg':
Duration: 00:41:53.23, start: 0.000000, bitrate: 30 kb/s
Stream #4:0: Audio: vorbis, 48000 Hz, mono, fltp, 86 kb/s
Metadata:
ENCODER : libsndfile
TITLE : fuzzynewest
File 'output5.ogg' already exists. Overwrite ? [y/N] y
[Parsed_amerge_0 @ 0x7f8b29f02d20] No channel layout for input 1
[Parsed_amerge_0 @ 0x7f8b29f02d20] Input channel layouts overlap: output layout will be determined by the number of distinct input channels
[flac @ 0x7f8b2b005600] encoding as 24 bits-per-sample
Output #0, ogg, to 'output5.ogg':
Metadata:
encoder : Lavf56.40.101
Stream #0:0: Audio: flac, 48000 Hz, stereo, s32 (24 bit), 128 kb/s (default)
Metadata:
encoder : Lavc56.60.100 flac
Stream mapping:
Stream #0:0 (vorbis) -> amerge:in0
Stream #1:0 (vorbis) -> amerge:in1
Stream #2:0 (vorbis) -> amerge:in2
Stream #3:0 (vorbis) -> amerge:in3
Stream #4:0 (vorbis) -> amerge:in4
amerge -> Stream #0:0 (flac)
Press [q] to stop, [?] for help
size= 100900kB time=00:33:53.94 bitrate= 406.4kbits/s
video:0kB audio:100441kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.457024%
OK so thanks to StackOverflow I see ffmpeg indeed takes the shortest channel but I don't see a flag to override that. :(
Downvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit
So I solved this with
amixI'll write a post about it soon.Downvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit
This is quite helpful. Quite disturbing that it cuts off the end though.
Downvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit
Yeah
amergetakes the shortest track, I solved this withamixI'll write a post about it soon.Downvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit
Congratulations @nutela! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPDownvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit