What is Hadoop?
Hadoop is an open source framework, it is a distributed system infrastructure, used to process big data. Hadoop was first proposed by Google as a basic concept, and later technically implemented by the Doug Cutting organization, and finally opened to the open source community. Doug Cutting’s son has a yellow, full-fed elephant. He named it Hadoop, and Doug Cutting borrowed this name.
Hadoop core architecture
1. Distributed file system HDFS
The traditional file system is stand-alone and cannot span different machines. HDFS (Hadoop Distributed FileSystem) is essentially designed for a large amount of data that can span hundreds of thousands of machines, but what you see is one file system instead of many file systems. For example, if you say that I want to get the data of /hdfs/tmp/file1, you are referring to a file path, but the actual data is stored on many different machines. As a user, you don't need to know these, just like you don't care about the tracks and sectors of the files on a single machine. HDFS manages this data for you.
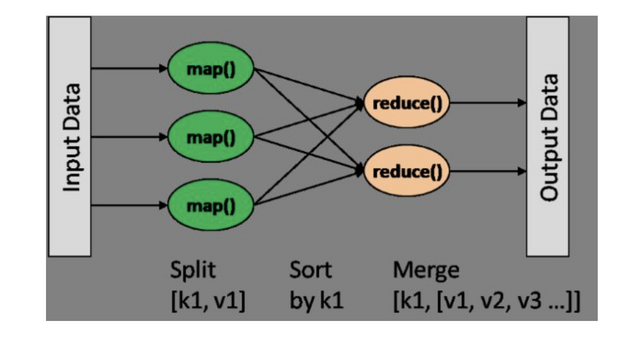
2.Map/Reduce model
Since the HDFS file system supports huge amounts of data, how to deal with the data? Although HDFS can manage the data on different machines as a whole for you, the data is too big. The data that a machine reads into P on T is even larger, and it may take days or even weeks for a machine to run slowly. For many companies, stand-alone processing is unbearable, and the Map/Reduce model solves a problem.
The Map/Reduce calculation model is simply that the Map phase is split into multiple subsets, the Reduce phase calculates the subsets separately, and finally the results are merged. For example, if the company bought a large basket of apples as a benefit, it needs to count how many apples there are. A quick and easy way is to distribute the apples to the colleagues Zhang San, Li Si, and Wang Wu present. Plus is the total number of apples.
What is the relationship between Hadoop, Hive, and Spark?
Hive is a data warehouse tool based on Hadoop. Since the MapReduce program is very cumbersome to write, hive will simplify it and translate the script and SQL language into a MapReduce program, and leave it to the calculation engine for calculation, and you will be freed from the cumbersome MapReduce program and written in a simpler and more intuitive language. The procedure is up.
MapReduce is the first-generation computing engine, and Spark is the second-generation. Because the MapReduce engine is too slow, it has not reached the popularity expected by people. So Spark appeared, which greatly enhanced efficiency. Spark can store the applications in the Hadoop cluster in memory, so the running speed is greatly improved.