In a week we'll see a Bitcoin (Cash) protocol upgrade that enables up to 32 MB blocks on the network. The critical people among us may ask how we are going to see the software deal with blocks that are significantly larger than what we're used to.
This is a blog from a series, previous: A roadmap for scaling Bitcoin Cash
Today I want to go a bit more in-depth into the UTXO database. The Unspent Transaction Outputs database.
Bitcoin is a chain of blocks, each block has lots of transactions and money is being moved in most of those transactions. A mistake most people make is to think that this is like bank accounts. I send 3 transactions to one person and they now have the total amount of that money on some account.
Bitcoin is much closer to cash. If you send 3 transactions to one person they need to spend each of those specifically. Much like a couple of coins stay individual coins in your wallet.
For any validating node to know that there is no cheating going on what we then need is a full account of all the outputs (or coins) that have not yet been spend. If someone is spending a coin not in that list, then they are cheating and we ignore them.
This full list is called the UTXO. The unspent transaction outputs. It is updated on each block to add the new ones and remove the spent ones.
Most used UTXO implementation
In most full nodes (the ones based on Bitcoin Core) there is a UTXO implementation that is based on a key/value store. A database of sorts.
There are various reasons why this is something I want to replace
First the most important one. The LevelDB database is known to be fragile and get corrupted. This can cause dramatic waiting times in order to re-create the database.
The Core devs copied blockchain info into the database, causing it to get slow and memory hungry.
It is impossible to use the old system in more than one thread. Multi core systems don't add much.
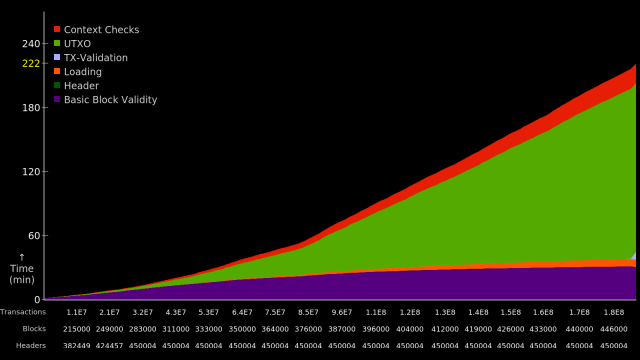
Profiling tests show that the database doesn't scale linearly. It gets slower the bigger it gets.
This is visible in the next image where the green area (time taken by the UTXO) has a 'knee' at around the 364000 blockheight.
What about a SQL database?
I went and wrote a simple test app to see how fast I could make the insertion of data into the a simple SQL database. It would read the actual blockchain and insert / delete rows based on the actual history of the chain. I published the code in a 'research-utxo' branch on github for those that want to see what I did.
The result was less than satisfactory. A database expert helped me design the schema and tweak the system, but the end result was very slow. It took about 3 minutes to do what the LevelDB could do in 10 seconds.
What I learned from this was that the disk-sync (to make sure that the in-memory state is exactly the same as on disk) was by far the slowest part. I got about 50% speed gain by turning off some sync, but the database told me that it could cause catastrophic data loss..
Bottom line, an out-of-the-box DB doesn't work.
This was confirmed by Bitpay open source dev Matias Alejo Garcia;
https://twitter.com/ematiu/status/984060032424792065
Custom DB
The realisation set in that the best way forward was to use my experience writing low-level software and my experience with Bitcoin to design a database specifically for the usecase of the unspent outputs database.
Unique features:
an output is written to the DB only once ever.
when an output is used, we delete the output.
lookup is based on the sha256 hash (32 bytes in size) combined with an output-index integer.
And one observation that is actually very useful;
it is Ok to lose your latest data as long as you have a 'checkpoint' where the data is consistent.
This last one is true because we still have the actual blocks that can be re-parsed to get from the latest checkpoint to the current state of the network. The reason this is very useful is because our largest bottleneck in the SQL case was that we required the state to be perfect at all times. Relaxing that requirement is going to avoid a lot of waiting time for the disk.
On Twitter I got one person objecting saying that reinventing databases is not the wisest choice. While he has a point, I would like to think that in 2018 there is very wide range of research publicly available about lots of techniques used in databases. There are plenty of general purpose open source databases available in the first place (LevelDB / RocksDB being examples of that).
It took me a week from idea to working implementation, one that is plenty fast as well. The reason for this is that I could reuse many designs and ideas that are common knowledge in computer science. If you know how a hashtable is implemented, you might recognise some parts of the unspent output database.
Today I pushed a first version of new classes to the Flowee database. all available under the Free software license GPL implementing a new UTXO DB. And I would like to share a bit about the design I put in there.
Design
The most important part of the design is that we know for a fact that entries in our database never get changed. Only deleted.
How I use this info is that I insert at first those items in a simple memory structure, this to keep inserts fast and IO-wait free.
Then in a second thread I push a lot of those outputs to disk. Just remembering their position on disk. And I delete them from memory.
When I need those items again, I just have to read the item from disk instead of from memory.
I always save to disk at the end of the file, I never go back and change the file. This again means we don't need to worry about synchronisation to disk because writes are never destructive.
If something didn't get saved properly, I just go back to an older position in the file and restart from there.
Staged databases
Some time ago a French guy asked if we should think about decommissioning the money that hasn't moved for, say 75 years. Because otherwise the UTXO would get too slow.
I thought that was an interesting problem. And I suggested a solution that I now integrated into this new layer.
In the Unspent Output Database I actually hide not just one but a series of databases. Each of them are the same design but they store outputs that are from a specific period in time.
I have one that covers the first 6 years of Bitcoin. The second covers the rest.
When I request if a payment is real, I first go to the most recent database and check, if there is no hit I go to the older one and all the way to the first database. This has the implication that for the vast majority of payments I will have no slowdown however long this system runs. Only when payments are made moving coins that are many years old does it take a little extra time.
Results
I wrote a test app that reads the actual blockchain and then uses the UTXO to check those transactions are actually moving existing money and I reached 15 million transactions processed in the span of 10 minutes on my 4-core Linux machine. This is various orders of magnitude better than the SQL databases I tried. I think its better than the LevelDB solution as well.
As a next step I need to actually integrate this into the Hub from Flowee in order to replace the LevelDB based solution we inherited from Core.
My wish is that we can improve on the stability of that solution and we should also be able to bring the initial sync time down. Flowee is currently clocked at approx 6 hours for initial sync (still faster than everyone else), I hope this improves on that time.
There is no content behind the paywall, but as an open source dev working on these hard problems making Bitcoin actually scale, tips are very much appreciated to allow me to continue doing this.
Bcash is a Roger way to take your money.
Downvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit