One question I often get is how to build a data team in a company. This is mostly asked by people who are doing a startup or thinking about starting one seriously. This question is followed by another set of questions. Two common ones are:
- What does a data scientist or data analyst or data engineer do? How are all these positions different?
- If I have to hire one data person, should I hire a data scientist or a data engineer?
I will try to answer the very first question (how to build out the data team) and the next question (how the roles differ) in this blog. Instead of explaining different data positions one by one, I will describe them as I explain how a company’s data organization evolves by talking about the roles they are playing. This is obviously purely my personal opinion based on my own experience.
Beginning of Data Organization
When a company is small, you don’t really have sizable data to process. Actually worrying about daily survival is probably a more important priority. But as the company grows, there will be more and more data which you want to get some (actionable) insights from for your business.
Most likely in the beginning your production database (for example MySQL) will be used as the source of truth. But it is the production database so running some massive queries against it isn’t a great idea. Once in awhile this type of queries will freeze the database causing the service to grind to a halt. Production engineers will be mad at whoever ran the queries and those who ran the queries would be scared to run them again.
On top of that, you will likely want to add different data sources which are not readily available in the production database so that you can do one stop querying (joining of different data sources from a single database) as far as data analysis is concerned. Doing this requires engineering’s help and since the production database isn’t necessarily for this type of additional data, they are not going to be receptive to doing this type of work.
Introduction of Data Warehouse
Have you heard about “data warehouse”? Data warehouse is a term referring to a scalable database which contains all the data an organization needs for data analysis purpose. As your data grows and the demand to analyze it grows, you better set up a separate and scalable database which is your data warehouse. That’s the single source of truth and one-stop shopping center as far as data is concerned. That’s your data warehouse.
I would say the beginning of true data journey in an organization starts with its introduction of data warehouse. As mentioned earlier, when it is really small, your production database can be it. A popular choice of data warehouse these days is Redshift from AWS (explaining what it is itself will be another article) but I have seen companies using Hive as well.
Introduction of ETL processes
Once you have your data warehouse, the next thing is to load important data you want to analyze to it. This process is called ETL (Extract, Transform and Load):
- Extract means extracting data from source (for example MySQL). Data sources can be MySQL, web access log, external data in FTP, AWS S3 and so on.
- Transform refers to changing the data format to the one you want.
- Load is about uploading it to the data warehouse.
- Eventual output of an ETL process is a table (structured data) in the data warehouse. Still relational database knowledge (and the familiarity with SQL) is important in the era of big data.
You can use any language to implement this ETL but Python seems to be the most popular choice at this point (I might be a bit biased by the way). Simple ETL can be entirely written in Python but more massive large data ETL will require some big data processing technology such as Hive and Spark. ETL is mostly batch processing oriented as opposed to processing data in realtime at least in the beginning.
Managing ETL processes
When you have a handful of ETL processes, you can just use cronjob (or Jenkins) to schedule and manage them. Once you have a lot more processes with complex dependencies among them, you need some kind of scheduler or workflow engine which allows you to schedule jobs at certain times or based on data availability.
Airbnb’s Airflow is gaining a big momentum but there are lots of other options (Pinterest’s Pinball, LinkedIn’s Azkaban, Yahoo’s Oozie, Luigi, AWS Data Pipeline, Coursera’s Dataduct, …).
At Udemy (an online learning marketplace startup) we are currently using Pinball which is written in Python after evaluating a few different options mentioned above. In Pinball, you can visualize job dependencies like this:
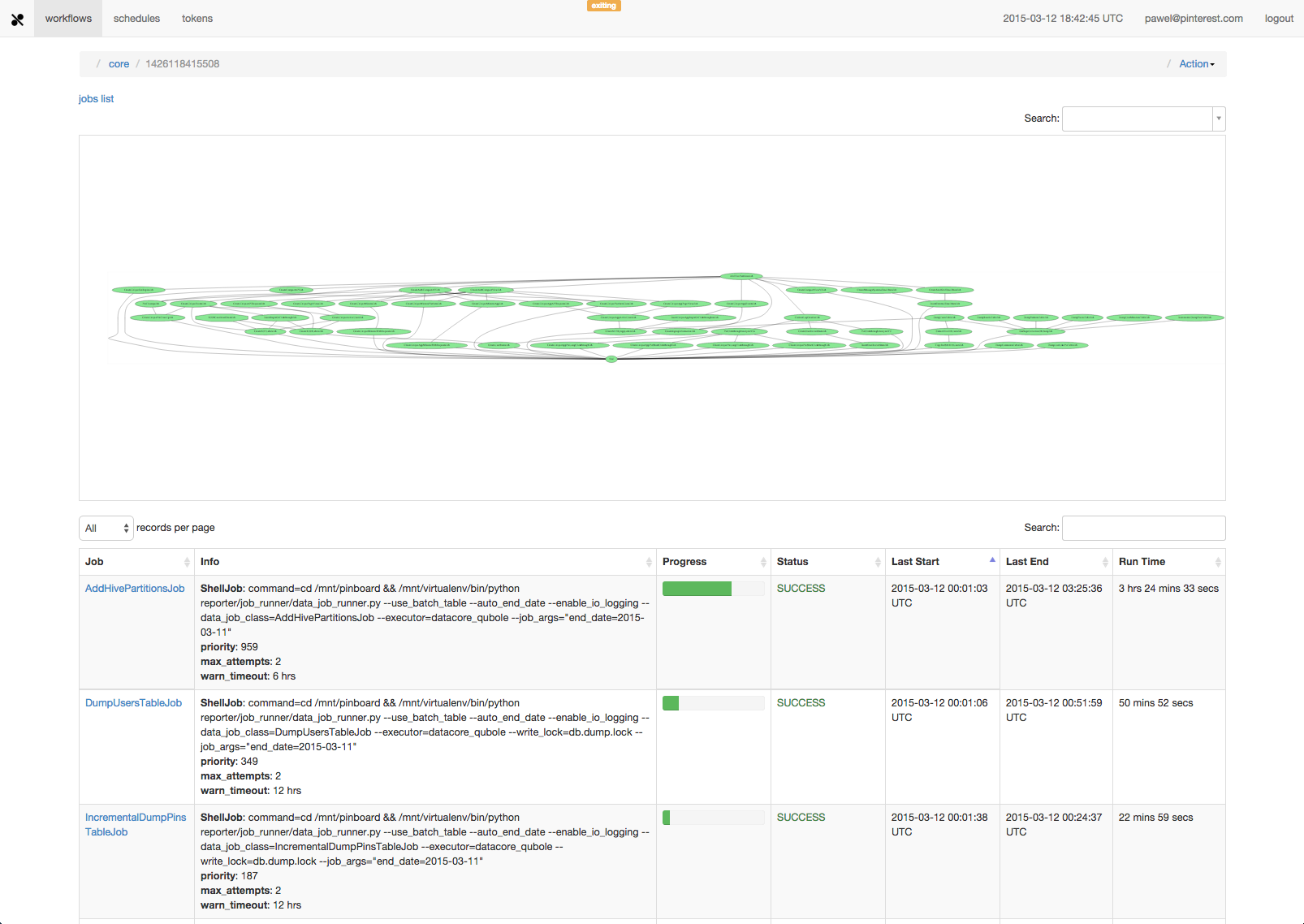
Who manages data warehouse and ETL processes?
Who will be managing this data warehouse and implementing ETL processes? That’s the main job of data engineers. It is one of the hardest jobs in software engineering since many data sources are not in their control so on a given day some ETL processes will be always broken. These need to be fixed as soon as possible.
Also there will be a lot of requests from different teams to add more data to the data warehouse and worst of all the engineers really don’t know how the data is consumed in the end. Most of the time they are data code monkeys :). Having a big picture or some kind of feedback is very important for the engineers to be excited about their work and is an important responsibility of the data engineering management.
Learn from Data and Predict the Future
Once you have lots of ETL processes, you will end up having lots of tables in the data warehouse. It can be a few thousand tables with lots of data. Who would know all of these tables? It is not a good idea to open up access to all these detailed (more like raw) tables to employees of your company since they can’t know all of them and it will cause more confusions and can lead to very wrong analysis.
Creation of Summary tables
A better way of doing is to create summary tables around key entities of your business. In the case of Udemy, key entities are students, instructors and courses. Most data questions will be likely around one of these:
- How many new students were enrolled in the last month? Breakdown by countries?
- What’s the revenue breakdown of new users vs. existing users?
- Who are the top instructors in terms of revenue or enrollment?
- The summary table could be designed around certain actions such as search. For example, what’s the top search terms by revenue in the last one week?
Once you have a few of these summary tables, most users don’t need to know all the gory details of tables and their dependencies. They can just use them to get what they need. From these questions, you might get some ideas. This summary table building requires deep domain knowledge and understanding of your business and product.
Who creates the summary tables?
Creating and updating these summary tables itself is another ETL processes. They can be written by data engineers but it is better suited for data analysts through writing SQL (not necessarily by coding) mainly because this requires deep domain knowledge of business and product.
Data analysts generate internal reports to meet requests from different business units (sales, growth, product and so on) using SQL. To do this, they might need to join a lot of different tables and create new summary tables periodically so that querying can be simpler and faster. But some requests can’t be answered by summary tables and in such case one-off ad-hoc work is required. If there are similar data requests over and over, that indicates a need for another summary table.
Visualization
Not everyone can write SQL queries. Even if you can, writing SQL to get your insights is cumbersome. Visualization and easy-to-access dashboards are very important in terms of democratizing data throughout the company.
There are ranges of choices here: Tableau, Looker, ChartIO, AWS Quicksight and so on. There is some limitation but Airbnb’s Caravel seems very promising (it allows only one materialized view - in other words no support for JOIN). Most of these tools use the SQL interface.
Using data to predict the future
Once you have comprehensive summary tables, you can hopefully answer business units’ questions on data without much issue. The next step as a data organization is to use this data in your data warehouse to improve your actual service itself. You can think of this as providing a feedback loop (both positive and negative feedbacks). Essentially from user actions you learn something about users. It can range from some aggregated insights (what works the best in general) to individual preferences (personalization). This is the main responsibility of data scientist.
This work can be summarized as building a predictive model by learning from the past data. Using the past data as examples, you build a training set and then build a prediction model. Once the model is built the next step is to push this into production.
This sounds easy but building a model requires many iterations. If each iteration has to be done manually it will be slow and prone to errors. Depending on the size of the training set, you might need to use Hive and Spark. In short building a machine learned model needs a scalable data infrastructure.
Data Analyst vs. Data Scientist
I briefly touched upon different roles taken by data scientists and data analysts but let me summarize just to make a bit clearer (again this is purely my personal view):
- Data analyst serves internal customers by writing reports or creating internal dashboards.
- Data scientist is more external facing by writing a predictive model (rule based or machine learned). The data scientist’s primary contribution is to help the end users of the service. Examples are building search ranking models or recommendation models.
In terms of skillset, the underlying skills are quite similar. Some statistics knowledge (with R) and familiarity with SQL is a must. One big distinction in my opinion is whether you can code. In my definition a data scientist should be able to code so that prototyping can be done without anybody’s help. Here coding is mostly needed so that the scientist can clean up data and create features. This is in particular because the scale of data you have to deal with would be much larger.
In terms of career path, many data analysts want to be a data scientist at some point in their career. Because of this putting data analysts and data scientists under the same organization provides a better career path for data analysts. Also it can minimize potentially redundant work done by different data teams. But this discussion itself is worth another article.
Conclusion
I briefly shared my personal definition of data engineer, data analyst and data scientist. Just to make it more entertaining and practical, I explained how a data organization typically evolves together.
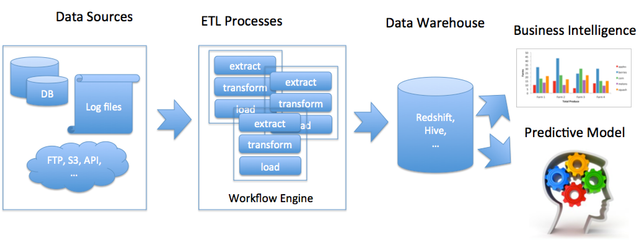
Ideally the process above needs to form a feedback loop so that there is a continuous learning.
Before closing, if you are wondering what my answer for the 2nd question in the opening (“If I have to hire one data person, should I hire a data scientist or a data engineer”) is, it is data engineer. You need data infrastructure to learn from your data. Frankly in the beginning of data organization journey data scientist isn’t really needed unless you already have sizable and clean data which is somewhat unlikely.
In the next blog, I will share my personal opinion on optimal team structure and collaboration model among data teams. I don’t think there is one-size-fits-all structure or model so I will just list different structures I have seen or heard about with pros and cons.
Congratulations @belderking! You have completed some achievement on Steemit and have been rewarded with new badge(s) :
Click on any badge to view your own Board of Honor on SteemitBoard.
For more information about SteemitBoard, click here
If you no longer want to receive notifications, reply to this comment with the word
STOPDownvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit
✅ @belderking, congratulations on making your first post! I gave you an upvote!
Please give me a follow and take a moment to read this post regarding commenting and spam.
(tl;dr - if you spam, you will be flagged!)
Downvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit
Congratulations @belderking! You received a personal award!
You can view your badges on your Steem Board and compare to others on the Steem Ranking
Do not miss the last post from @steemitboard:
Vote for @Steemitboard as a witness to get one more award and increased upvotes!
Downvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit