
Ich habe in meinem letzten Beitrag IPFS - Das System verstehen einen Überblick über das Schema geben. Dabei war für mich der Begriff "Merkle DAGs" neu. Die Theorie habe ich beim letzten mal geklärt. Heute möchte ich mit euch schauen, wie das in der Praxis aussieht.
Wir starten mit einer Testdatei "super_testbild.jpg" mit ca. 2,6MB.
Verzeichnis von E:\tmp\ipfs\go-ipfs_v0.4.13_windows-amd64\go-ipfs\test_content
12.02.2018 12:07 <DIR> .
12.02.2018 12:07 <DIR> ..
12.02.2018 10:45 2.666.661 super_testbild.jpg
Wir adden die Datei ins IPFS Netzwerk:
E:\tmp\ipfs\go-ipfs_v0.4.13_windows-amd64\go-ipfs>ipfs.exe add test_content\super_testbild.jpg
2.54 MB / 2.54 MB [============================================================================================================================================] 100.00% 0s
added QmNTv6SgoLnRtqXJ6WN6HS9VPZGQMAYS21cbhoH9aDYRXj super_testbild.jpg
Dadurch erhalten wir den Hash QmNTv6SgoLnRtqXJ6WN6HS9VPZGQMAYS21cbhoH9aDYRXj
Jetzt schauen wir mal, was mit unserer Datei im IPFS passiert:
ipfs ls: list, Zeigt alle Teile und deren Größe.
ipfs object links: Zeigt ebenfalls alle Links des Objektes an. Würde den gleichen Output liefern.
E:\tmp\ipfs\go-ipfs_v0.4.13_windows-amd64\go-ipfs>ipfs ls -v QmNTv6SgoLnRtqXJ6WN6HS9VPZGQMAYS21cbhoH9aDYRXj
Hash Size Name
QmeFdcvrTbtWovyCBfHQuvxmuarjoYfBh3oa5DHibkU7tU 262158
Qmd55Udt99hNPDA5F2XbTtQJP2EK7Wp125mzEFRvmcfpz1 262158
QmYVWMkpBhV5vchj2cJoqsuXX2MWmb9Ywavc5J1Q3DC7tq 262158
QmdaAxVzzwnK8m1EpYi46Efjri16omUMHKV3evm4agkyPk 262158
QmNnTFtYt9fuPfMYB7bVDXDy4UTd8xxDm41kjvEqVJWGaT 262158
QmS1b7j6YbTWktzK6Ly2Ak1vmbM5EhwvZTAzXVc76CHr11 262158
QmRABaJE2j7MxKTkoasYKYXVHbkznic1Wo9EiPh6nGFeog 262158
Qmf4qXc9eVch83g8FcrMG6GVfSh3AxcFQzdfujmxBnCVjK 262158
QmQ2RGtmKQ473y1FGGZm3yCtiJ5pp7FGCW46PVfVfLpEfp 262158
QmQrb76m1mYbwV9Qwgw1exkADbBEBTLke1ETMgiZXNdxzt 262158
QmSw84fUPaQx5s5QyMHzAw8YnrkoqCoCn4fY3nMnYMVRLd 45235
Es fällt auf, dass unsere "Datei" in Blöcke zu je 256KB (262158/1024) geteilt.
Um es etwas zu veranschaulichen, habe ich das mal als Grafik abgebildet:
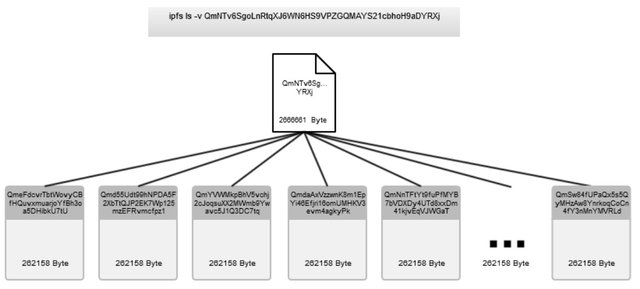
In den untergeordneten Hashes sind jetzt entweder weitere Verweise und die Daten enthalten.
Ich definiere an der Stelle unseren QmNTv6SgoLnRtqXJ6WN6HS9VPZGQMAYS21cbhoH9aDYRXj als Startblock und alle anderen als untergeordnete Blöcke.
Wenn meine "Datei" im IPFS noch weitere untergeordnete Blöcke hätte, also eine weitere Subebene existieren würde, könnte ich weiter mit ipfs object links danach suchen.
Als Test mach ich das mal und wir schauen ob es weitere Verweise gibt. Wir starten mit dem ersten untergeordneten Block QmeFdcvrTbtWovyCBfHQuvxmuarjoYfBh3oa5DHibkU7tU
ipfs object links -v QmeFdcvrTbtWovyCBfHQuvxmuarjoYfBh3oa5DHibkU7tU
Hash Size Name
ipfs object links -v Qmd55Udt99hNPDA5F2XbTtQJP2EK7Wp125mzEFRvmcfpz1
Hash Size Name
ipfs object links -v QmYVWMkpBhV5vchj2cJoqsuXX2MWmb9Ywavc5J1Q3DC7tq
Hash Size Name
ipfs object links -v QmdaAxVzzwnK8m1EpYi46Efjri16omUMHKV3evm4agkyPk
Hash Size Name
ipfs object links -v QmNnTFtYt9fuPfMYB7bVDXDy4UTd8xxDm41kjvEqVJWGaT
Hash Size Name
ipfs object links -v QmS1b7j6YbTWktzK6Ly2Ak1vmbM5EhwvZTAzXVc76CHr11
Hash Size Name
ipfs object links -v QmRABaJE2j7MxKTkoasYKYXVHbkznic1Wo9EiPh6nGFeog
Hash Size Name
ipfs object links -v Qmf4qXc9eVch83g8FcrMG6GVfSh3AxcFQzdfujmxBnCVjK
Hash Size Name
ipfs object links -v QmQ2RGtmKQ473y1FGGZm3yCtiJ5pp7FGCW46PVfVfLpEfp
Hash Size Name
ipfs object links -v QmQrb76m1mYbwV9Qwgw1exkADbBEBTLke1ETMgiZXNdxzt
Hash Size Name
ipfs object links -v QmSw84fUPaQx5s5QyMHzAw8YnrkoqCoCn4fY3nMnYMVRLd
Hash Size Name
Keiner unserer untergeordneten Blöcke verweist weiter.
Was ich noch nicht weiß, ist die Größe unsere Startblocks. Theoretisch müsste der sehr klein sein, da er nur aus Verweisen auf anderen Blöcke besteht. Schauen wir mal!
ipfs block stat - gibt uns die Größe eines Blocks zurück
ipfs block stat QmNTv6SgoLnRtqXJ6WN6HS9VPZGQMAYS21cbhoH9aDYRXj
Key: QmNTv6SgoLnRtqXJ6WN6HS9VPZGQMAYS21cbhoH9aDYRXj
Size: 537
Stimmt, unser Startblock ist nur 537 Byte klein
Der Umkehrschluss davon ist, dass wir eigentlich in jedem Block jetzt die Daten auslesen können müssten. Probieren wir das mal.
ipfs cat - Liest den Inhalt auf der Konsole vor.
Ich nehme als ersten Test einfach mal den letzten Block QmSw84fUPaQx5s5QyMHzAw8YnrkoqCoCn4fY3nMnYMVRLd
ipfs cat QmSw84fUPaQx5s5QyMHzAw8YnrkoqCoCn4fY3nMnYMVRLd
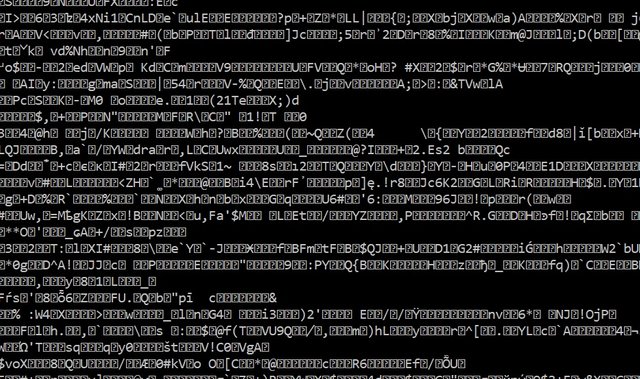
Sieht gut aus. Ich versuche den Inhalt einer Binärdatei auf der Konsole darzustellen. Das muss genau so aussehen :)
Wenn ich jetzt den Startblock angebe, müsste er eigentlich automatisch allen Verweisen folgen und mir den gesamten Inhalt der Datei "vorlesen".
Da wird also wieder das gleiche (für mich) Kauderwelsch ankommen. Da ich aber weiß, dass es ein .jpg ist leite ich die Ausgabe einfach in eine Datei um, die ich mir hinterher anschaue.
ipfs cat QmNTv6SgoLnRtqXJ6WN6HS9VPZGQMAYS21cbhoH9aDYRXj > mein_vorglesenes_bild.jpg
Das Bild ist vollständig da und ich kann es mir wieder anschauen.
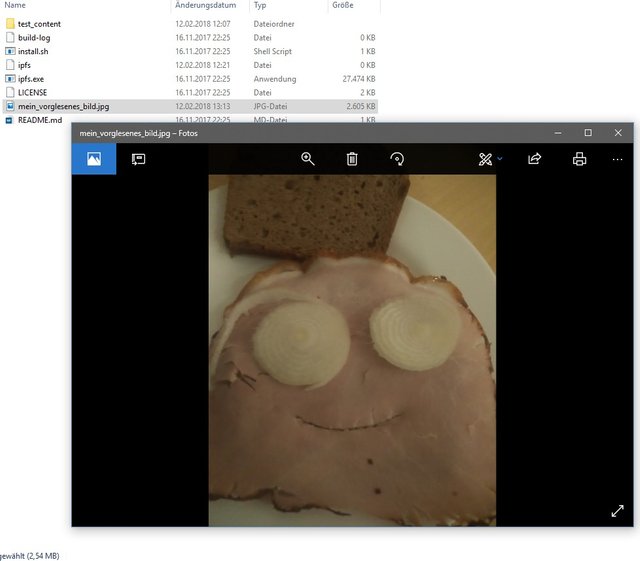
Das hat funktioniert, wie erwartet. Jetzt müsste es ja auch möglich sein einfach alle untergeordneten Blöcke manuell zusammen zu fügen ohne, dass ich den Startblock benutze. Testen wir mal!
ipfs cat QmeFdcvrTbtWovyCBfHQuvxmuarjoYfBh3oa5DHibkU7tU Qmd55Udt99hNPDA5F2XbTtQJP2EK7Wp125mzEFRvmcfpz1 QmYVWMkpBhV5vchj2cJoqsuXX2MWmb9Ywavc5J1Q3DC7tq QmdaAxVzzwnK8m1EpYi46Efjri16omUMHKV3evm4agkyPk QmNnTFtYt9fuPfMYB7bVDXDy4UTd8xxDm41kjvEqVJWGaT QmS1b7j6YbTWktzK6Ly2Ak1vmbM5EhwvZTAzXVc76CHr11 QmRABaJE2j7MxKTkoasYKYXVHbkznic1Wo9EiPh6nGFeog Qmf4qXc9eVch83g8FcrMG6GVfSh3AxcFQzdfujmxBnCVjK QmQ2RGtmKQ473y1FGGZm3yCtiJ5pp7FGCW46PVfVfLpEfp QmQrb76m1mYbwV9Qwgw1exkADbBEBTLke1ETMgiZXNdxzt QmSw84fUPaQx5s5QyMHzAw8YnrkoqCoCn4fY3nMnYMVRLd > zusammengebaut_ohne_startblock.jpg
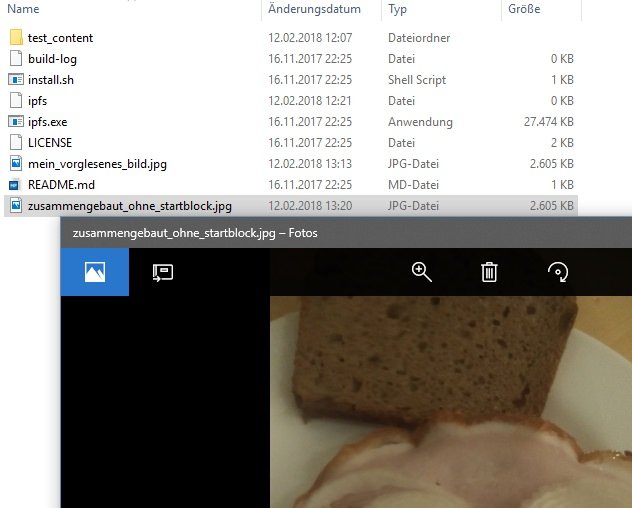
Funktioniert, wie erwartet!
Eigentlich alles ganz logisch. Gut es mal in der Praxis nachvollzogen zu haben.
Fazit und Gelerntes
- Ich habe neue IPFS Befehle gelernt, hier noch mal als Übersicht:
| Befehl | Nutzen |
|---|---|
| ipfs block stat | Größe eines Blocks auslesen. |
| ipfs ls | Zeigt die Blöcke, auf die verwiesen wird und deren Größe. |
| ipfs object links | Ist analog zu "ipfs ls". |
| ipfs cat | Liest den Inhalt von Blöcken aus. Löst dabei aber Verweise direkt auf. |
- Für mich war auch neu, dass meine Datei in 256KB "kleine" Blöcke unterteilt wird.
Ich hoffe dieses kleine Praxisbeispiel war für euch anschaulich und hilfreich. Wenn ihr Anmerkungen habt, bitte schreibt einen Kommentar! Ich würde mich auch freuen, wenn ihr mir einfach schreibt, was euch sonst noch an dem Thema interessiert. Was habt ihr für Fragen? Was soll ich mir demnächst mal anschauen?
This is a test comment, notify @kryzsec on discord if there are any errors please.
Being A SteemStem Member
Downvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit
Ah interessant, bedeutet das eigentlich, wenn der Startblock größer als diese Grenze werden würde, dass dann der erste Block auch nur ein Verweisblock auf eine Untermenge an Blöcken wird?
Als Tipp eventuell bei deinen Konsolenbeispielen würde ich eventuell anstatt:
nur
schreiben. Mich würde vor allem dann als nächstes interessieren wie das mit dem verteilen ist und woher weiß z.b. ipfs.io dann genau wo der angeforderte Hash liegt, bzw. wie kommunizieren die knoten =)
Downvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit
Schön veranschaulichtes Beispiel :)
Vor allem die neuen Befehle nochmal aufzulisten finde ich super ... so kann man dies auch direkt heranziehen und sich mal selbst daran versuchen. Bin ja wieder etwas spät ... Deshalb warte ich mal was du in den nächsten beiden Posts geschrieben hast xD
Gut zu Wissen ist noch, dass die Dateien wirklich in 256KB Blocks geschnitten werden. Das erklärt damit den enormen CPU Aufwand, wenn man 2 GB Dateien hochlädt. Wenn ich mich nicht verrechnet habe sind das bei 2.000.000 KB fast 8.000 Hashes, die erzeugt werden müssen (2GB 2.000.000 KB / 256KB = 7812,5 also 7813 Hashes)?
Downvoting a post can decrease pending rewards and make it less visible. Common reasons:
Submit