
Mit regulären Ausdrücken, auch Regex genannt, wie beispielsweise [abcde], lassen sich Zeichenketten (Strings) prüfen, durchsuchen und bearbeiten. Das ist oftmals sehr nützlich. Reguläre Ausdrücke werden auf die eine oder andere Art von den meisten Websites genutzt, beispielsweise um die Besucher von der HTTP Version der Website auf die HTTPS Version umzuleiten. Falls du diesen Ausdrücken noch nie so wirklich begegnet bist, so schau mal in die .htaccess Datei eines Content Management Systems wie WordPress, Drupal, Joomla oder TYPO3. Meistens wirst du fündig werden.
Auf den ersten Blick sind diese Ausdrücke völlig unverständlich, aber es ist so eine Art Programmiersprache und irgendwie auch eine ganz eigene und faszinierende Welt :).
Der Ausdruck [abcde] sucht beispielsweise ein a, ein b, ein c, ein d oder ein e. Du könntest das auch so ausdrücken: [a-e]. Das sieht doch schon viel übersichtlicher aus und funktioniert mit allen Zeichen, also auch mit Ziffern [123456] oder, in der abgekürzten Variante [1-6]. Diese Ausdrücke heissen Zeichenklassen.
Um die Ausdrücke sinnvoll benutzen zu können, benötigst normalerweise eine Programmiersprache und die entsprechenden Kommandos und Funktionen. In PHP sind das beispielsweise die Funktionen preg_match für das Prüfen und Finden, sowie preg_replace für das Ersetzen von Zeichenketten.
Wenn du die Zeichenkette "Bahnhofstrasse 12" überprüfen willst, ob sich dort ein Zeichen der Menge der Zeichen 1 bis 6 befindet, würde der Code in PHP etwa so aussehen:
$re = '/[123456]/m'; $str = 'Bahnhofstrasse 12'; preg_match_all($re, $str, $matches, PREG_SET_ORDER, 0);
Falls du PHP gerade nicht "zur Hand" hast, kannst du die Beispiele auch online ausprobieren (https://regex101.com). Das Ausprobieren ist meines Erachtens sehr wichtig, weil die Ausdrücke doch schnell unübersichtlich werden. Die Online Prüfung liefert auch eine Erklärung, was passiert und die Anzahl der Treffer (Matches). Es kann ja sein, dass Zeichen mehrfach vorkommen. Leider sind die Ergebnisse nicht in jeder Implementierung und Komplexität zu 100% gleich. Auch der Onlinetest kommt bei komplexen Ausdrücken an Grenzen, da er ja auch in "nur" einer bestimmten Programmiersprache erstellt wurde. Um das System prinzipiell zu verstehen und sich auch automatisch Programmcode erstellen zu lassen, den man dann weiterentwickeln kann, eignen sich Onlinetests jedoch hervorragend.
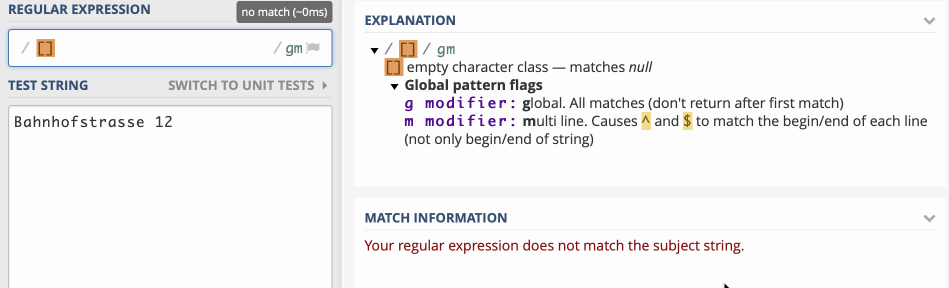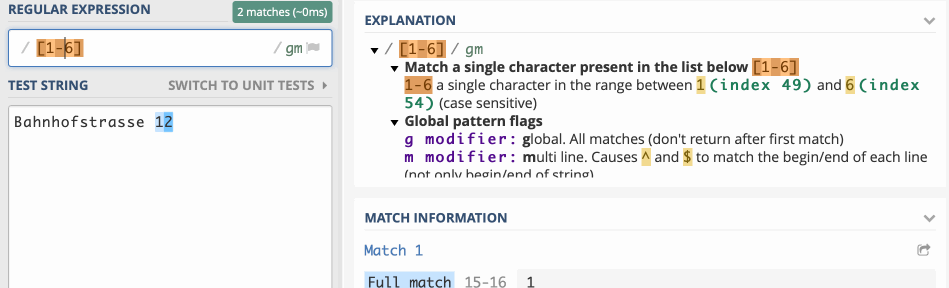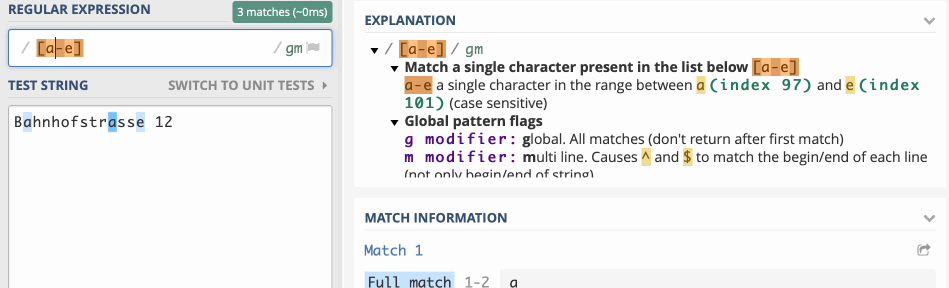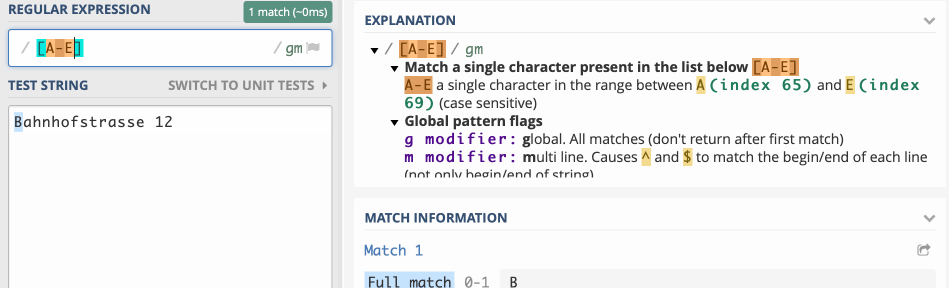
Reguläre Ausdrücke prüfen einen String im Browser https://regex101.com
Metazeichen
Es gibt Zeichen, die du suchst und es gibt Metazeichen. Das ist hier im Blog gar nicht so einfach ausdrückbar, weil die runden Klammern ebenfalls zu den Metazeichen zählen und der Punkt ebenfalls etwas besonderes ist.
Das sind die Metazeichen:
.\|^?*+[]{}()Zeichenklassen
Im obigen Beispiel haben wir die Zeichen in Metazeichen [123456] eingeschlossen und zur Zeichenklasse gemacht [1-6]. Da diese Zeichenklassen sehr oft benötigt werden (Ziffern von 0-9, Buchstaben A-Z und a-z) gibt es auch vordefinierte Zeichenklassen. die mit einer "Abkürzung" aufgerufen werden können.
[0123456789] entspricht [0-9] entspricht der Abkürzung \d
Manchmal benötigt man auch die Negation einer Zeichenklasse, also die Überprüfung, ob keine Zeichen dieser Zeichenklasse vorhanden sind. Das macht man mit den ^ Zeichen
[^0-9] findet alles ausser 0 bis 9 und für [^0-9] gibt es auch eine Abkürzung, nämlich \D
Zeichenklassen können kombiniert werden.
[abcde] und [123456] entspricht [abcde123456] entspricht [a-e1-6]
Hier ein gebräuchliches Beispiel:
[a-zA-Z0-9] entspricht [a-zA-Z\d]
Zeichenklassen können auch voneinander abgezogen werden (Differenz), also beispielsweise die Buchstaben a-z aber nicht d-f. Das && ist die entsprechende Verbindung
[a-z&&[^d-f]]
Bei Zeichenketten geht es ja oft um "Worte", die durch ein Leerzeichen getrennt sind. Während ich diesen Artikel schreibe, zählt der Gutenberg Editor beispielsweise die Worte. Der Text muss also irgendwie zerlegt werden. Ein Wort erkennt man daran, dass ein Leerzeichen folgt, oder ein Tabulatorzeichen, oder ein Zeilenumbruch ("Newline" oder \n). Diese Zeichen heissen Whitespaces.
\w ist das Wortzeichen
\W ist das Gegenteil, also kein Wort
\s ist der Whitespace (der Platz zwischen den Worten, also Leerzeichen, Tabulatoren, usw)
\S ist das Gegenteil, also kein Whitespace
Der Punkt . steht nicht für das Satzzeichen am Ende, sondern für ein beliebiges Zeichen ausser dem Zeilenumbruch. Wenn man den Punkt als Zeichen meint, muss man ihn mit einem Backslash "maskieren", damit er nicht als Metazeichen erkannt wird.
Wenn du immer noch liest ohne das dir das Hirn platzt, so gehe ich davon aus, dass dir mittlerweile viele Beispiele selbst einfallen, die sich hervorragend mit regulären Ausdrücken überprüfen lassen könnten. Ich denke da an Passworte, die bestimmte Zeichen enthalten, Eingaben, bei denen das erste Zeichen gross geschrieben werden soll, Postleitzahlen, IBANs, E-Mail Adressen (siehe ganz oben) und vieles andere mehr.
Wiederholungen
Wenn du mehrere gleiche Zeichen überprüfen willst kannst du Wiederholungen nutzen. Die werden in geschweiften Klammern dargestellt.
- a{4} entspricht viermal dem Zeichen a hintereinander, also aaaa
- a{3,5} entspricht drei bis fünf mal dem Zeichen a hintereinander, also aaa, aaaa oder aaaaa
- a{3,} entspricht mindestens drei mal dem Zeichen a hintereinander, also aaa. aaaa oder aaaaa würden auch zählen, aaaaaaaaaa allerdings auch.
Auch hier gibt es gebräuchliche Abkürzungen:
- a* bedeutet, das a beliebig oft oder gar nicht auftauchen kann, entspricht also der Schreibweise a{0,}
- a+ bedeutet, das a beliebig oft auftreten kann aber mindestens einmal auftauchen muss, entspricht also der Schreibweise a{1,}
- a? prüft, ob a auftaucht oder nicht, entspricht also a{0,1}
Grenzen
Um die Suche zu optimieren, kann man sich an Grenzen orientieren. Immer am Zeilenanfang sucht man mit ^, am Zeilenende mit $, an der Wortgrenze mit \b, and der "Nicht-Wortgrenze", also quasi auf dem Anfang des "Whitespaces" zwischen den Worten mit \B.
Gruppen
Mit dem senkrechten Strich lässt sich eine Gruppe definieren. Der Ausdruck (Hauptstrasse|Hauptstr.) findet beide Schreibweisen.
Mit $1 oder \1 lassen sich die Ergebnisse der Gruppen wiederverwenden oder auch "fangen".
Drupal nutzt dieses "fangen" beispielsweise bei der Überprüfung ob der Browser komprimierte CSS Dateien akzeptiert. Wenn das der Fall ist, ändert Drupal die Dateiendung vor dem Aufruf. Wir haben hier den "Suchen und Ersetzen" Fall.
# Serve gzip compressed CSS files if they exist and the client accepts gzip.
RewriteCond %{HTTP:Accept-encoding} gzip
RewriteCond %{REQUEST_FILENAME}\.gz -s
RewriteRule ^(.*)\.css $1\.css\.gz [QSA]
Der Ausdruck ^(.*).\css bedeutet:
Suche an der Grenze Zeilenanfang ^ nach einer Gruppe beliebiger Zeichen (.*), die die Dateiendung \.css haben. Um den Punkt bei der Dateiendung suchen zu können, muss er mit einem Backslash maskiert werden, damit das System ihn nicht für den Punkt für ein beliebiges Zeichen hält.
Im Ausdruck $1\.css\.gz nutzt die Rewrite Engine des Webservers den bereits untersuchten Dateinamen mit dem Parameter $1 und hängt eine andere Dateiendung an, schreibt den Namen also um.
Das ist ganz schön clever, oder ?
Man muss so etwas ja erstmal gedanklich verdauen, aber die Möglichkeiten sind schon atemberaubend, wenn man ein wenig darüber nachdenkt. Es gibt natürlich viel mehr Abkürzungen und Konstrukte, als ich hier beschrieben habe.
Fazit
Auch wenn reguläre Ausdrücke einen manchmal sehr schnell überfordern, so sind sie doch eine sehr elegante und schnelle Methode um Zeichenketten zu überprüfen und gegebenenfalls zu ändern.
Links
- Apache mod_rewrite Introduction
- Online Test: regex101.com, debuggex.com/
- Sehr anschauliches Tutorial (Deutsch) https://danielfett.de/2006/03/20/regulaere-ausdruecke-tutorial/
- Wikipedia: https://de.wikipedia.org/wiki/Regulärer_Ausdruck
tl;dr: Reguläre Ausdrücke sind interessant und nützlich
Posted from my blog with SteemPress : https://blog.novatrend.ch/2019/05/20/regulaere-ausdruecke/