
If the terms "catastrophic forgetfulness" and "regularization of weights" you have nothing to say, read on: try to understand everything in order.
What we love neural networks for
The main advantage of neural networks over other machine learning methods is that they can recognize deeper, sometimes unexpected patterns in data. In the learning process, neurons are able to respond to the information received in accordance with the principles of generalization, thereby solving their task.
The areas where the network is already being used in practice include medicine (for example, cleaning the readings from noise, analysis of the effectiveness of treatment), the Internet (associative information retrieval), the economy (forecasting currency rates, automatic trading), games (for example, go) and others. Neural networks can be used for almost anything because of its versatility. However, the magic pill they are not, and that they began to function properly, requires a lot of preliminary work.
Neural network training 101
One of the key elements of the neural network is the ability to learn. Neural network is an adaptive system that can change its internal structure on the basis of incoming information. This effect is typically achieved by adjusting the weight values.
Connections between neurons in adjacent layers of the neural network are numbers that describe the significance of the signal between two neurons. If the trained neural network responds correctly to the input information, then there is no need to adjust the weight, and otherwise, using any training algorithm, you need to change the weight, improving the result.
!Typically, this is done by using the error back propagation method: for each of the training examples, the weights are adjusted to reduce the error. It is believed that with the right architecture and a sufficient set of training data, the network will sooner or later learn.!
There are several fundamentally different approaches to learning, in relation to the task. The first-training with the teacher. In this case, the input is a pair: an object and its characteristic. This approach is used, for example, in image recognition: training is carried out on the basis of marked images and manually placed labels that are drawn on them.
The most famous of these is the ImageNet database. In this formulation of the problem training is not much different from, for example, the recognition of emotions, which deals Neurodata Lab. Networks demonstrate examples, it makes an assumption, and, depending on its correctness, weights are adjusted. The process is repeated until the accuracy is increased to the desired values.
The second option is teaching without a teacher. Typical tasks are the clustering and the selected formulation of the problem of anomaly detection. In this scenario, the true training data labels are not available to us, but there is a need to find patterns. Sometimes, a similar approach is used to pre-train the network in the problem of learning with the teacher. The idea is that the initial approximation for the scales was not a random decision, but already able to find patterns in the data.
Well, the third option — training with reinforcement-a strategy based on observations. Imagine a mouse running through a maze. If she turns left, she gets a piece of cheese, and if she turns right, she gets a shock. Over time, the mouse learns to turn only to the left. The neural network operates in the same way, adjusting the weight, if the final result — "painful". Reinforcement training is actively used in robotics: "did the robot hit the wall or remained unharmed?". All tasks related to the games, including the most famous of them — AlphaGo, are based on training with reinforcement.
Retraining: what is the problem and how to solve it
The main problem of neural networks is retraining. It consists in the fact that the network "remembers" the answers instead of catching patterns in the data. Science has contributed to the birth of several methods to combat retraining: this includes, for example, regularization, normalization of battles, data and others. Sometimes the retrained model is characterized by large absolute values of weights.
!The mechanism of this phenomenon is something like this: the source data is often highly multidimensional (one point from the training sample is represented by a large set of numbers), and the probability that at random the point will be indistinguishable from the release, the larger the dimension. Instead of "entering" a new point into the existing model, correcting weights, the neural network seems to come up with an exception: we classify this point by one rule, and others — by another. And such points usually many.!
The obvious way to deal with this kind of retraining is regularization of weights. It consists of either an artificial restriction on the values of the weights, or adding the penalty to the extent of mistakes at the stage of learning. This approach does not solve the problem completely, but most often improves the result.
The second method is based on limiting the output signal, rather than the values of the weights — it's about normalizing the battles. At the training stage, the data are submitted to the neural network batching packs. The output values for them can be anything, and so their absolute values are greater than, the higher the weight values. If we subtract one value from each of them and divide the result into another, the same for the whole batch, then we will keep the qualitative ratio (the maximum, for example, will still be the maximum), but the output will be more convenient for processing it with the next layer.
The third approach does not always work. As already mentioned, the retrained neural network perceives many points as abnormal, which you want to process separately. The idea is to build up a training sample so that the points appear to be of the same nature as the original sample, but are generated artificially. However, a large number of related problems are immediately born here: selection of parameters for increasing the sample, a critical increase in learning time, and others.
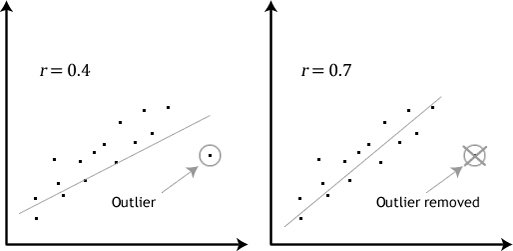
The effect of removing abnormal values from the training set of data
A separate problem is the search for real anomalies in the training sample. Sometimes it is even considered as a separate task. The image above shows the effect of excluding an abnormal value from the set. In the case of neural networks, the situation will be similar. However, finding and excluding such values is not a trivial task. Special techniques are used for this purpose
one network – one problem or "problem of catastrophic forgetting»
Working in dynamically changing environments (e.g. financial) is difficult for neural networks. Even if you have successfully trained your network, there is no guarantee that it will not stop working in the future. Financial markets are constantly changing, so what worked yesterday may just as well "break" today.
Here researchers either have to test a variety of network architectures and choose the best one, or use dynamic neural networks. The latter "monitor" the changes in the environment and adjust their architecture in accordance with them. One of the algorithms used in this case is the MSA (multi-swarm optimization) method.
!Moreover, neural networks possess a certain feature, which is called catastrophic forgetting (catastrophic forgetting). It boils down to the fact that the neural network can not be consistently taught several tasks — on each new training sample all the weight of neurons will be rewritten, and the past experience will be "forgotten".!
Of course, scientists are working to solve this problem. The developers of Deep Mind recently proposed a way to deal with catastrophic forgetfulness, which is that the most important weight in the neural network when performing a certain task and artificially made more resistant to change in the learning process on task B.
The new approach is called Elastic Weight Consolidation due to the analogy with the elastic spring. Technically, it is implemented as follows: each weight in the neural network is assigned a parameter F, which determines its importance only within a certain task. The larger F for a particular neuron, the more difficult it will be to change its weight when learning a new task. This allows the network to" remember " key skills. The technology gave way to" highly specialized " networks in some tasks, but proved to be the best in the sum of all stages.

Reinforced black box
Another difficulty in working with neural networks is that the ins are actually black boxes. Strictly speaking, in addition to the result, the neural network can not pull anything, even statistics. At the same time, it is difficult to understand how the network makes decisions. The only example where this is not the case is convoluted neural networks in recognition problems. In this case, some intermediate layers make sense of feature maps (one link shows whether some simple pattern has encountered in the original picture), so the excitation of different neurons can be traced.
Of course, this nuance makes it quite difficult to use neural networks in applications when errors are critical. For example, Fund managers cannot understand how a neural network makes decisions. This leads to the fact that it is impossible to correctly assess the risks of trading strategies. Similarly, banks that use neural networks to model credit risks will not be able to tell why this very client has such a credit rating now.
Therefore, neural network developers are looking for ways to circumvent this limitation. For example, we are working on so-called rule extraction algorithms (rule-extraction algorithms) to improve the transparency of the architecture. These algorithms extract information from the neural networks either in the form of mathematical expressions, and symbolic logic, either in the form of decision trees.
Neural networks are just a tool
Of course, artificial neural networks actively help to master new technologies and develop existing ones. Today, at the peak of popularity is the programming of unmanned vehicles, in which neural networks in real time analyze the environment. IBM Watson has been discovering new applications, including medicine, from year to year. Google has an entire division that deals directly with artificial intelligence.
However, sometimes there is a neural - not the best way to solve the problem. For example, networks are lagging behind in areas such as high-resolution imaging, human speech generation, and in-depth analysis of video streams. Working with symbols and recursive structures are also given to the neural networks is not easy. This is also true for question-answering systems.
Initially, the idea of neural networks was to copy and even recreate the mechanisms of brain functioning. However, humanity still needs to solve the problem of the speed of neural networks, to develop new algorithms for logical inference. Existing algorithms are at least 10 times inferior to the brain, which is unsatisfactory in many situations.
At the same time, scientists have not yet fully decided in which direction to develop neural networks. The industry is trying to bring neural networks as close as possible to the model of the human brain, and generate technology and conceptual schemes, abstracting from all the "aspects of human nature." Today — it's something like" open work " (if you use the term Umberto Eco), where almost any experiments are acceptable, and fantasy – acceptable.
The activity of scientists and developers engaged in neural networks requires deep training, extensive knowledge, the use of non — standard techniques, since the neural network itself is not a "silver bullet" that can solve any problems and problems without human intervention. It is a comprehensive tool that can do amazing things in skillful hands. And he's still got it.
